Inuktitut Computing
The UQAILAUT Project
Inuktitut Transcoder
- Unicode
- Unicode \uxxxx1
- Unicode &#xxxx;2
- Unicode URL Encoding %xx3
- Nunacom
- ProSyl
- AiPaiNunavik
- Roman Alphabet
- select the font or format you want to transcode from,
- select the font or format you want to transcode to,
- write the text in the 'Text to transcode' box, and
- click the 'Transcode' button.
Each time you select a different font or format to transcode to, the text in the 'Text to transcode from' box is automatically transcoded to the new format; no need to click again on the 'Transcode' button.
You may also select the Inuktitut Unicode Font for the boxes 'Text to transcode from' and 'Text transcoded to' when the text in those boxes is in the 'Unicode' format.

Unicode \uxxxx
A Unicode character is written in this format as \u immediately followed with 4 hexadecimal digits representing the numerical value of the Unicode code. For example, the 7-syllabic-character word  is written in this format as the following 7-\uxxxx-character string: \u14c7\u14d7\u14c7\u1403\u1466\u1450\u1585. This format is used for example in Java and Javascript strings to reprensent Unicode characters in a string constant.
is written in this format as the following 7-\uxxxx-character string: \u14c7\u14d7\u14c7\u1403\u1466\u1450\u1585. This format is used for example in Java and Javascript strings to reprensent Unicode characters in a string constant.
Unicode &#xxxx;
This is the format of the numeric decimal HTML entity. HTML entities are used in HTML documents to represent characters with their numerical Unicode code without worrying about the encoding (ISO, UTF, etc.). For example, the two inuktitut characters  can be displayed using the two HTML entities ᕙᐃ instead of the equivalent UTF-8 sequence of 6 codes (3 for each syllabic character).
can be displayed using the two HTML entities ᕙᐃ instead of the equivalent UTF-8 sequence of 6 codes (3 for each syllabic character).
Unicode URL Encoding %xx
URL encoding is used to transmit non ASCII codes in URLs (addresses) of internet documents and in data of HTML forms. In this encoding, spaces are replaced with '+' characters, and every non ASCII code is replaced with a sequence of 1, 2, 3 or more %xx triplets representing the hexadecimal codes of its UTF-8 encoding. For example, the character ![]() (unicode 5465), the UTF-8 representation of which is the sequence of hexadecimal codes E1, 95 and 99, is written %E1%95%99 in URL encoding.
(unicode 5465), the UTF-8 representation of which is the sequence of hexadecimal codes E1, 95 and 99, is written %E1%95%99 in URL encoding.
AI
In Nunavik, in addition to the three series of I, U and A characters, there is a 4th serie: the AI characters, which transcribe the diphtong [εi], similar to the 'a' in the English word 'face'. Abandoned a long time ago because there was not enough room for them on the electric typewritter ball, they were then transcribed with a combination of 'A' syllabic characters followed by the syllabic character 'I', even though this combination represents in reality something quite different, two distinct sounds: [a] and [i].
When transcoding from the 'Unicode' format, from the 'Roman Alphabet' format, and from the 'Nunacom' and 'ProSyl' fonts to any of the 'Unicode' formats, it is possible to specify what to do with regards to the AI characters and the A+I sequences:
- A+I → AIPAI : all A+I sequences are replaced with the corresponding AI characters (for example, becomes
 ).
). - AIPAI → A+I : all AI characters are replaced with the corresponding A+I sequences (for example, becomes ).
- As is : no replacement whatsoever.
Of course, in the inuttitut language of Nunavik, all A+I sequences are not AI characters; A+I and AI are different sounds. Since the transcoding which is done here affects all A+I (or all AI), the A+I and AI characters in the 'Text transcoded' box are highlighted, so that they can be easily spotted; each one can be clicked to toggle it from one form to the other, as shown in the next two figures.

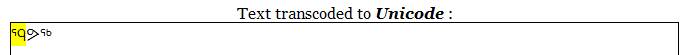
Input of syllabic characters
You will get all the necessary information about inputing Unicode syllabic characters HERE.You will get all the necessary information about inputing syllabic characters in Nunacom, ProSyl and AiPaiNunavik Legacy fonts HERE.
Display of syllabic characters
For those syllabic characters to display correctly on your screen, you will need to have the proper fonts installed on your computer. The fonts are available HERE.NRC Inuktitut Transcoder.